
// Java Binding for the OpenCL API
I am currently working on Java Binding for the OpenCL API using GlueGen (as used in JOGL, JOAL). The project started as part of my bachelor of CS thesis short after the release of the first OpenCL specification draft and is now fully feature complete with OpenCL 1.1. JOCL is currently in the stabilization phase, a beta release shouldn't be far away.
Overview - How does it work?
JOCL enables applications running on the JVM to use OpenCL for massively parallel, high performance computing tasks, executed on heterogeneous hardware (GPUs, CPUs, FPGAs etc) in a platform independent manner. JOCL consists of two parts, the low level and the high level binding.The low level bindings (LLB) are automatically generated using the official OpenCL headers as input and provide a high performance, JNI based, 1:1 mapping to the C functions.
This has the following advantages:
- reduces maintenance overhead and ensures spec conformance
- compiletime JNI bindings are the fastest way to access native libs from the JVM
- makes translating OpenCL C code into Java + JOCL very easy (e.g. from books or tutorials)
- flexibility and stability: OpenCL libs are loaded dynamically and accessed via function pointers
The hand written high level bindings (HLB) is build on top of LLB and hides most boilerplate code (like object IDs, pointers and resource management) behind easy to use java objects. HLB use direct NIO buffers internally for fast memory transfers between the JVM and the OpenCL implementation and is very GC friendly. Most of the API is designed for method chaining but of course you don't have to use it this way if you don't want to. JOCL also seamlessly integrates with JOGL 2 (both are built and tested together). Just pass the JOGL context as parameter to the JOCL context factory and you will receive a shared context. If you already know OpenCL and Java, HLB should be very intuitive for you.
The project is available on jogamp.org. Please use the mailinglist / forum for feedback or questions and the bugtracker if you experience any issues. The JOCL root repository is located on github, you may also want to take a look at the jocl-demos project. (If the demos are not enough you might also want to take a look at the junit tests)
Screenshots (sourcecode in jocl-demos project):
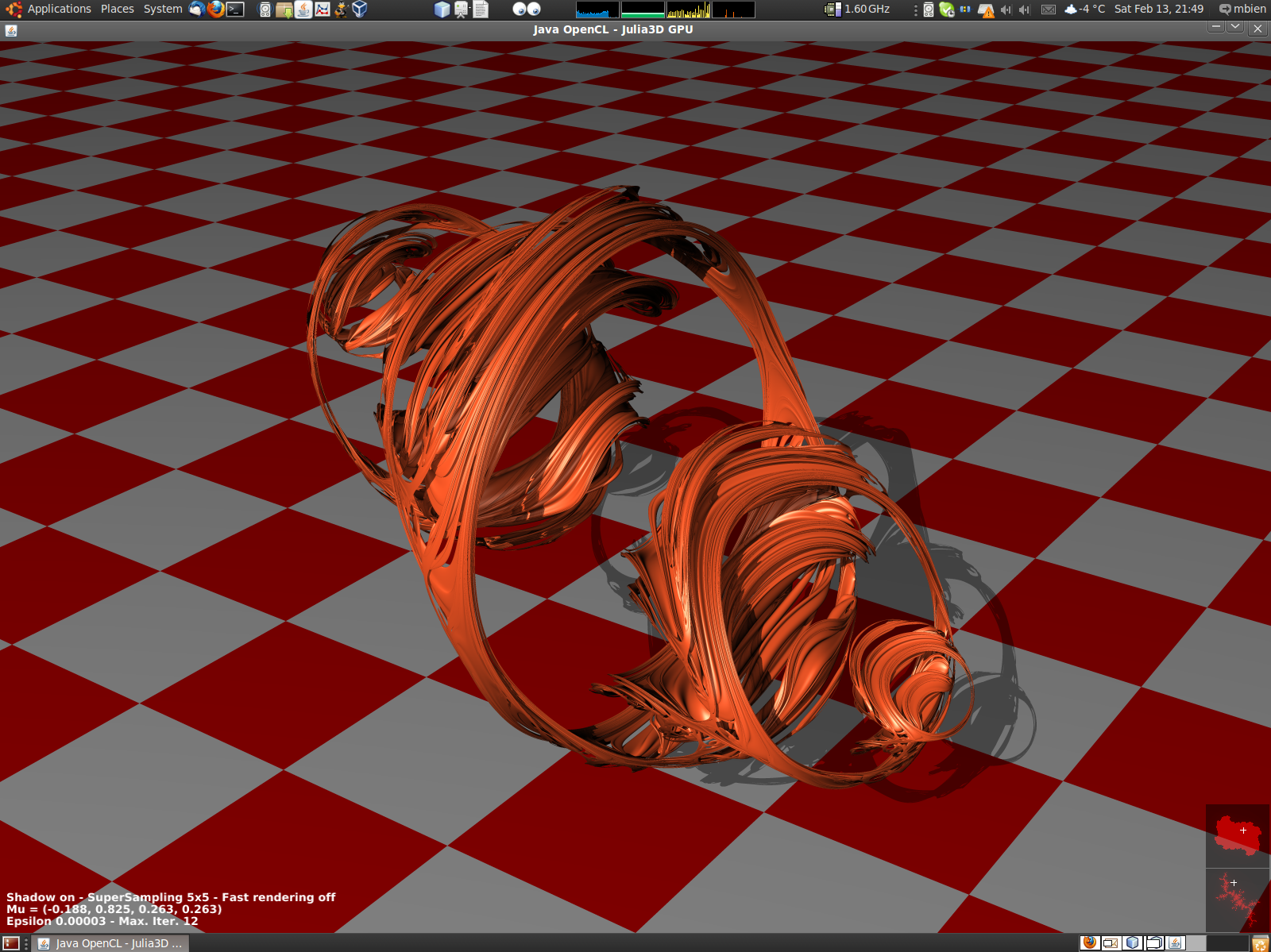

More regarding OpenGL interoperability and other features in upcoming blog entries.
The following sample shows basic setup, computation and cleanup using the high level APIs.
Hello World or parallel a+b=c
/**
* Hello Java OpenCL example. Adds all elements of buffer A to buffer B
* and stores the result in buffer C.
* Sample was inspired by the Nvidia VectorAdd example written in C/C++
* which is bundled in the Nvidia OpenCL SDK.
* @author Michael Bien
*/
public class HelloJOCL {
public static void main(String[] args) throws IOException {
// Length of arrays to process (arbitrary number)
int elementCount = 11444777;
// Local work size dimensions
int localWorkSize = 256;
// rounded up to the nearest multiple of the localWorkSize
int globalWorkSize = roundUp(localWorkSize, elementCount);
// setup
CLContext context = CLContext.create();
CLProgram program = context.createProgram(
HelloJOCL.class.getResourceAsStream("VectorAdd.cl")
).build();
CLBuffer<FloatBuffer> clBufferA =
context.createFloatBuffer(globalWorkSize, READ_ONLY);
CLBuffer<FloatBuffer> clBufferB =
context.createFloatBuffer(globalWorkSize, READ_ONLY);
CLBuffer<FloatBuffer> clBufferC =
context.createFloatBuffer(globalWorkSize, WRITE_ONLY);
out.println("used device memory: "
+ (clBufferA.getSize()+clBufferB.getSize()+clBufferC.getSize())/1000000 +"MB");
// fill read buffers with random numbers (just to have test data).
fillBuffer(clBufferA.getBuffer(), 12345);
fillBuffer(clBufferB.getBuffer(), 67890);
// get a reference to the kernel functon with the name 'VectorAdd'
// and map the buffers to its input parameters.
CLKernel kernel = program.createCLKernel("VectorAdd");
kernel.putArgs(clBufferA, clBufferB, clBufferC).putArg(elementCount);
// create command queue on fastest device.
CLCommandQueue queue = context.getMaxFlopsDevice().createCommandQueue();
// asynchronous write to GPU device,
// blocking read later to get the computed results back.
long time = nanoTime();
queue.putWriteBuffer(clBufferA, false)
.putWriteBuffer(clBufferB, false)
.put1DRangeKernel(kernel, 0, globalWorkSize, localWorkSize)
.putReadBuffer(clBufferC, true);
time = nanoTime() - time;
// cleanup all resources associated with this context.
context.release();
// print first few elements of the resulting buffer to the console.
out.println("a+b=c results snapshot: ");
for(int i = 0; i < 10; i++)
out.print(clBufferC.getBuffer().get() + ", ");
out.println("...; " + clBufferC.getBuffer().remaining() + " more");
out.println("computation took: "+(time/1000000)+"ms");
}
private static final void fillBuffer(FloatBuffer buffer, int seed) {
Random rnd = new Random(seed);
while(buffer.remaining() != 0)
buffer.put(rnd.nextFloat()*100);
buffer.rewind();
}
private static final int roundUp(int groupSize, int globalSize) {
int r = globalSize % groupSize;
if (r == 0) {
return globalSize;
} else {
return globalSize + groupSize - r;
}
}
}
VectorAdd.cl
// OpenCL Kernel Function for element by element vector addition
kernel void VectorAdd(global const float* a,
global const float* b,
global float* c, int numElements) {
// get index into global data array
int iGID = get_global_id(0);
// bound check (equivalent to the limit on a 'for' loop)
if (iGID >= numElements) {
return;
}
// add the vector elements
c[iGID] = a[iGID] + b[iGID];
}
Nice post,btw i have been trying some renderings in JOGL .Can u suggest any good resource for the same?Does Opencl is suited for workstation environments for its full potential?...thanks!
Posted by max on February 19, 2011 at 05:07 PM CET #
Hi max, for JOGL getting started resources take a look at the tutorial section on the wiki: http://jogamp.org/wiki/index.php/Jogl_Tutorial
concrete renderings and demo project vids can be found in the stream section:
http://jogamp.org/stream/ (or on our blog aggregator)
JOCL + workstation environment? Probably yes. Best case for OpenCL is if you can run on the GPU and CPU. It all depends what workstation you have. But the requirements are not that high usually.
Posted by michael bien on February 19, 2011 at 06:01 PM CET #